Class Demo: Scraping your Facebook posts with BeautifulSoup
It has been a while since my last post. The corona crisis really altered my schedule and plans for 2020. But we need to adapt, move forward and proceed to our new normal. I am lucky right now that I am able to write again, be able to breathe freely.
To the reader, sending you virtual hugs. I know that we are in rough times, but this too shall pass.
This post is a demonstration I used in my Web Scraping class for Eskwelabs. The goal is to scrape facebook posts (your own) and make a Word Cloud from it.
Data Science is not only about fancy algorithms, statistics and math. It is also about credibly and creatively sourcing your data. Given that the bulk of data is in the internet hiding in the backend or scattered in the frontend of websites, ethical web scraping (also called as data mining/web crawling) is indeed a handy technique.
The Cambridge Analytica Scandal took its toll and changed the data mining landscape giving focus to data ownership and privacy. Personal data of millions of Facebook users where scraped and used without consent for political advertising and campaigns.
It was a good thing that in 2018, the European Union pushed through implementing the General Data Protection Regulation (GDPR) that put privacy of people with their digital data at a premium.
Because of this a lot of tech companies mandated that their users will have the option to download their personal data (although it is unclear if these data is complete). At the very least we have a sense of ownership and visibility to our own data. If ever Facebook sells my info at least I know what info they got from me. And maybe think of how they might use this data. Let’s start scraping!
Step 1: Download Facebook Data
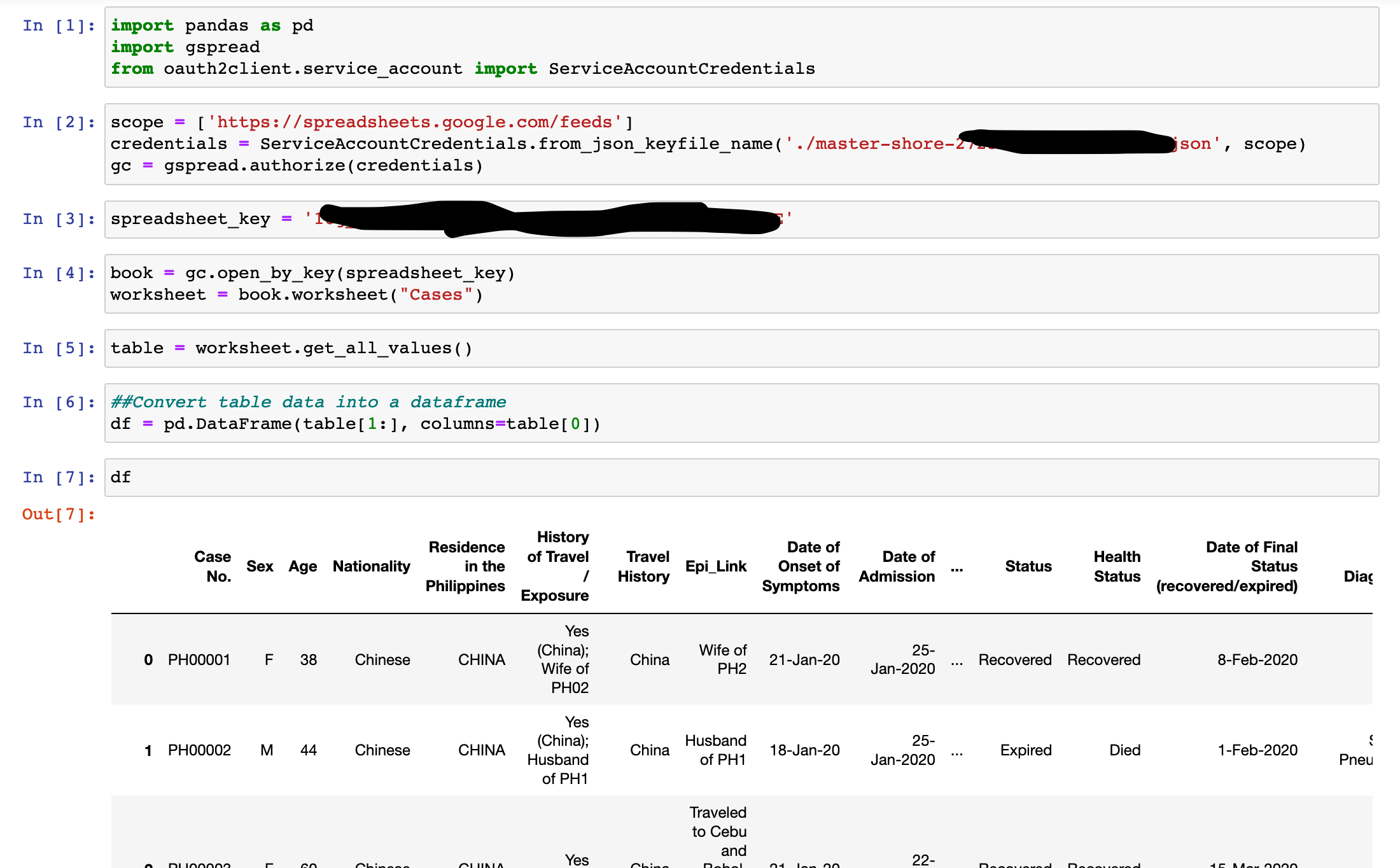
Log-in to your facebook account. Go to settings and click download your information.
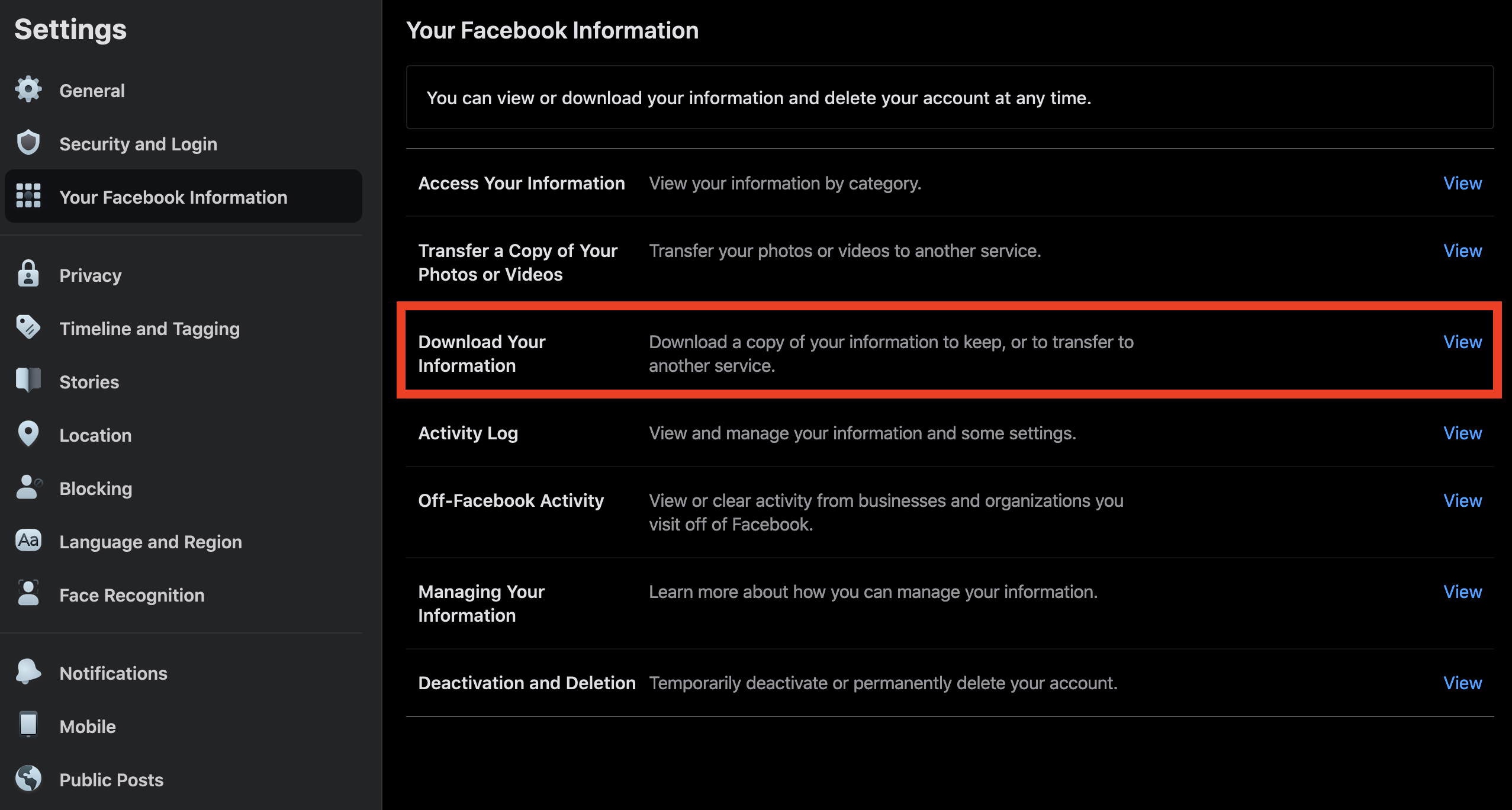
For the purposes of this tutorial/demo, we are only interested in your posts. So untick all check boxes except for posts.
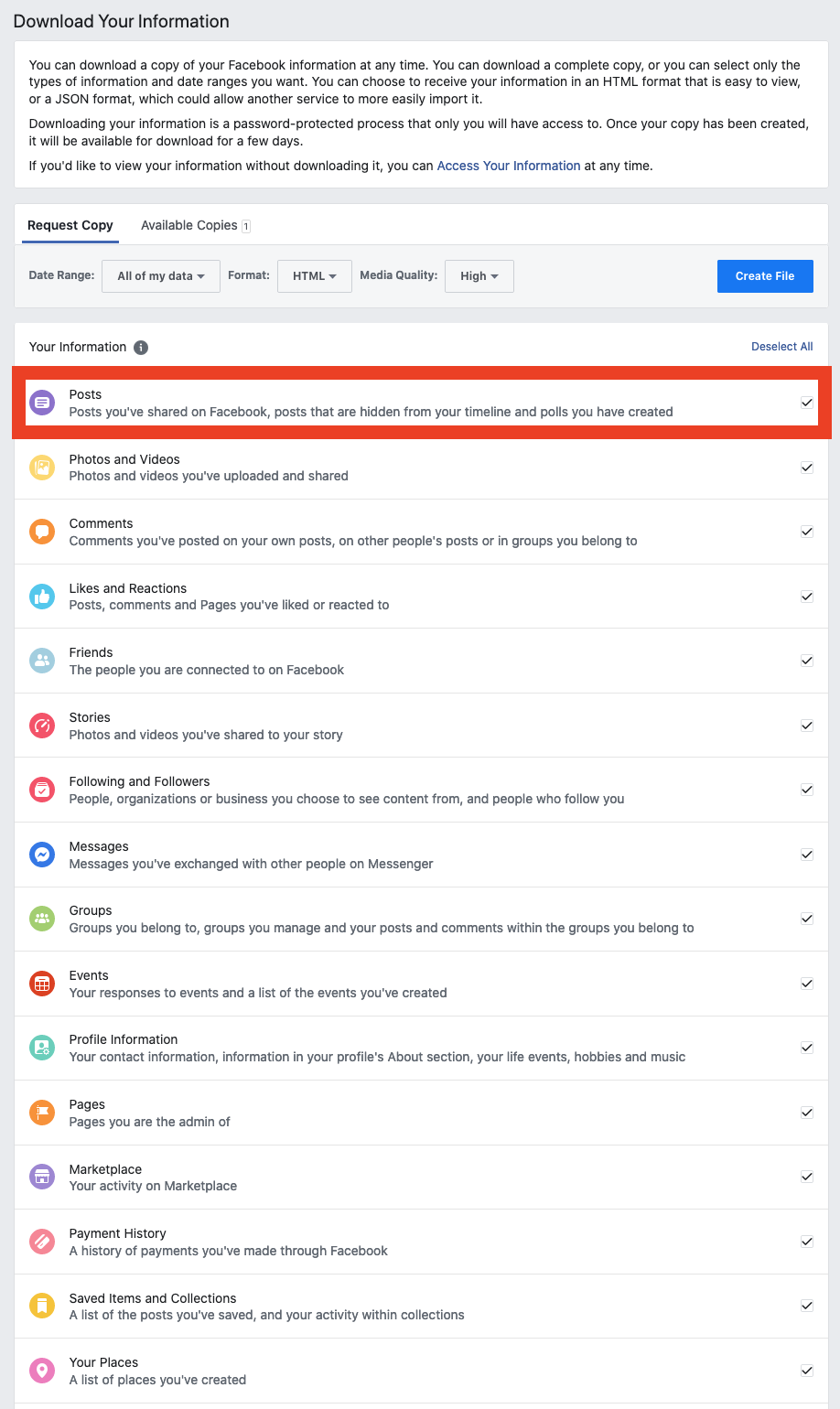
Here are the recommended filters:
- Date Range: All of my data
- Format: HTML
- Media Quality: Low (for faster download, we are interested to just texts anyway)
Click create file. You will be notified when it is ready to download. You will be prompted to download a zip file. Download and unzip it.
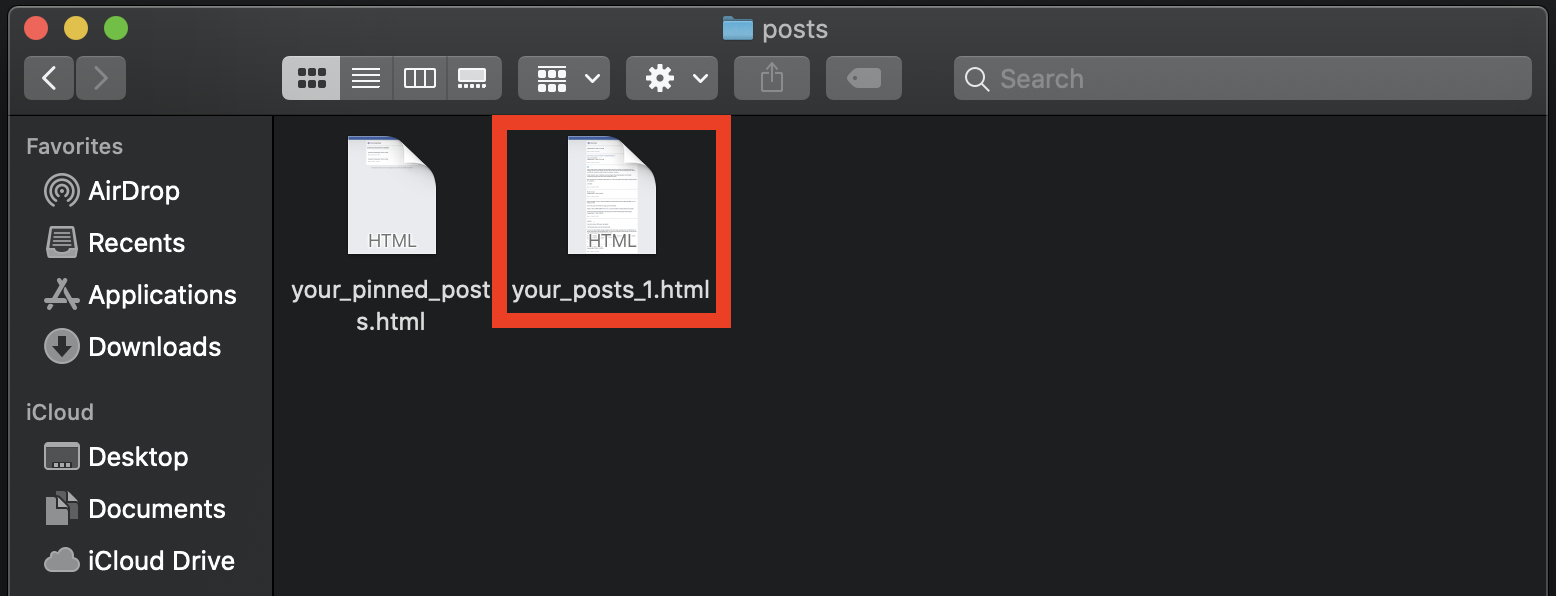
Open the unzipped folder, find the posts folder and locate the your_posts_1.html file.
Now let’s do us some Python 😁
You need to install BeautifulSoup and WordCloud
We now use beautiful soup to make a hot fudge of html mess.
To get the text of posts that I posted, let us check first the source code using my favorite browser’s (MOZILLA FIREFOX) inspector. Right click on a post and click inspect element (or whatever counterpart you have with your browser but I say switch to FIREFOX, the most secure browser).
Navigate along and do some pattern recognition to identify the correct class to filter. My guess would be _2pin.
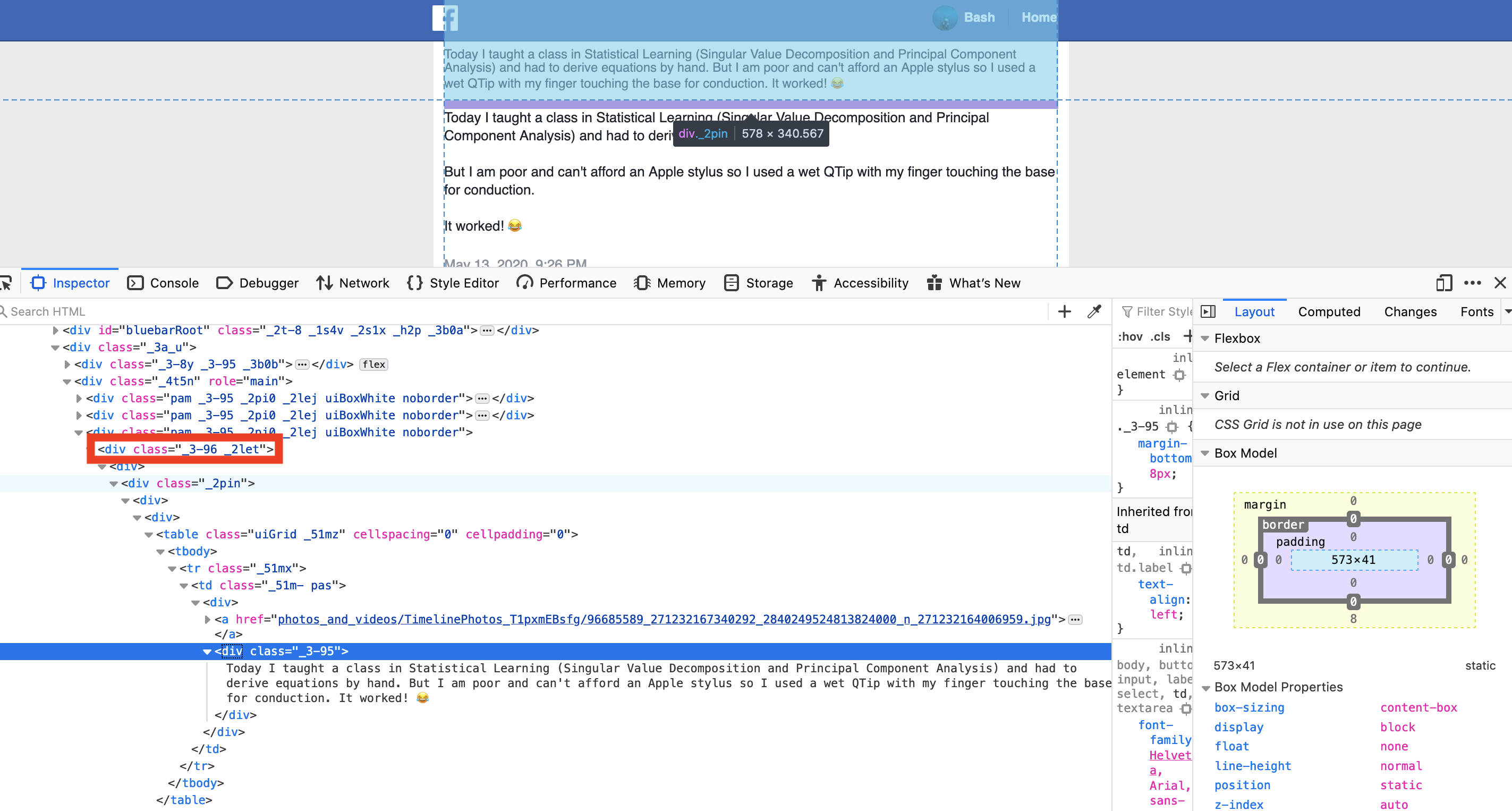
So let’s find all the div’s and filter all classes in _2pin. Checking the contents, we are correct that _2pin captures all of the posts. The following code demonstrates how it’s done. I made a list x to contain all of the posts.
We concatenate the list into one string then we visualize the words using Word Cloud.
You will notice that there are some words that are not really relevant like https, PM. We technically call them stop words in Natural Language Processing (NLP).
We remove them,
And here is our final output:

In summary, we did a quick demonstration on how to download your data from Facebook, use BeautifulSoup to parse it, and create a wordcloud from scraped text. Scraping can be expanded to many applications in business and industry problems e.g. for data augmentation in competition and market research. Stay tuned for more tutorials on web scraoing, next would be scraping from APIs.
References:
Questions? Contact me via LinkedIn. I’m also on GitHub with the username albertyumol.